
![]()

Certainly! Let’s delve into Peer-to-Peer Replication in SQL Server, covering its architecture, configuration, use cases, and best practices.
1. Introduction to Peer-to-Peer Replication
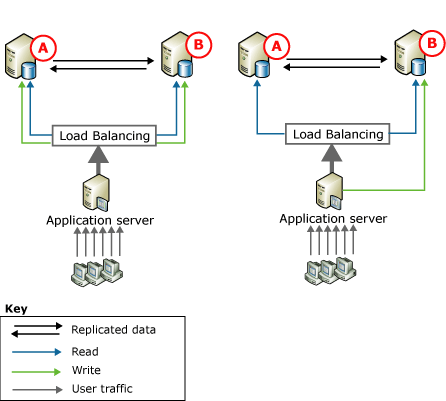
Peer-to-Peer (P2P) Replication in SQL Server is a topology where each node (server) acts as both a publisher and a subscriber. Unlike traditional replication models, where data flows in a unidirectional manner, P2P replication allows data to flow bidirectionally between all participating nodes. This setup ensures that each node has a complete copy of the database, providing high availability and load balancing.
Key Features:
- Bidirectional Data Flow: All nodes can send and receive data.
- High Availability: If one node fails, others can continue operations.
- Load Balancing: Distributes read and write operations across multiple nodes.
- Fault Tolerance: Reduces the risk of a single point of failure.
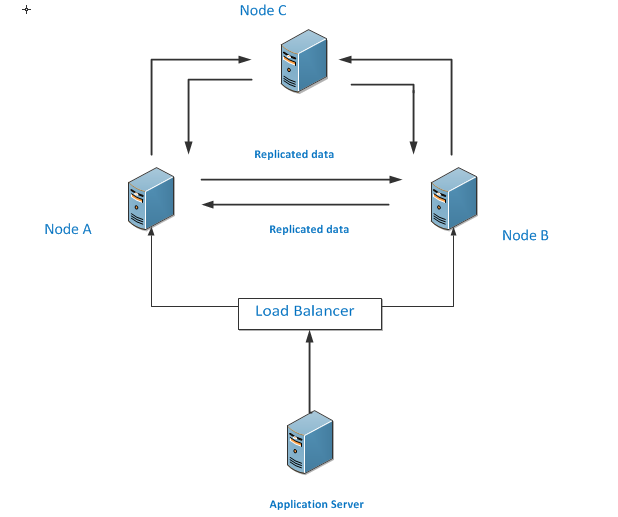
2. Architecture of Peer-to-Peer Replication
In a P2P replication setup:
- Publisher: Each node acts as a publisher, making data available for replication.
- Subscriber: Each node also acts as a subscriber, receiving data from other nodes.
- Distributor: Each node has its own distribution database, eliminating the single point of failure associated with a centralized distributor.
Diagram:
[Node A] ↔ [Node B] ↔ [Node C]
↑ ↑ ↑
└──────────────┴──────────────┘
Load Balancer
Source: SQLShack
3. Configuring Peer-to-Peer Replication
Prerequisites:
- SQL Server Enterprise Edition: P2P replication is supported only in the Enterprise edition.
- Identical Schema: All participating databases must have identical schemas and data.
- No Row or Column Filtering: Filtering is not supported in P2P replication.
- Unique Publication Names: Each publication must have a unique name across all nodes.
- Independent Distribution Databases: Each node must have its own distribution database.
Configuration Steps:
- Configure Distribution on All Nodes:
- Set up the distribution database on each node.
- Create a Publication:
- On the first node, create a new publication using the “Peer-to-Peer Transactional Publication” type.
- Enable Peer-to-Peer Topology:
- Right-click the publication, select “Properties,” and enable the peer-to-peer topology.
- Initialize Subscribers:
- Take a full backup of the publication database and restore it on each subscriber node.
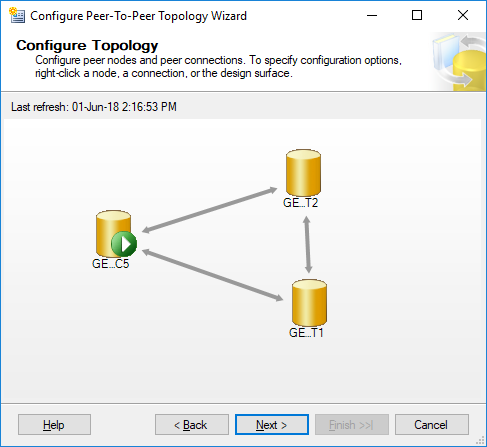
- Configure Peer-to-Peer Topology:
- Use SQL Server Management Studio (SSMS) to configure the topology, ensuring all nodes are aware of each other.
- Start Replication Agents:
- Start the Log Reader and Distribution Agents on each node to begin data replication.
Source: SQLShack
4. Conflict Detection and Resolution
In P2P replication, conflicts can occur if the same data is modified at multiple nodes simultaneously. SQL Server provides mechanisms to detect and handle such conflicts:
- Conflict Detection: Enabled through the
sp_configure_peerconflictdetectionstored procedure. When a conflict is detected, the Distribution Agent stops, and the system enters an inconsistent state until the conflict is resolved. - Conflict Tables: For each published table, a corresponding conflict table is created (e.g.,
conflict_dbo_Orders). These tables store conflicting rows for manual resolution. - Conflict Alerts: Configure alerts to notify administrators when conflicts occur.
Source: SQLServerCentral
5. Use Cases for Peer-to-Peer Replication
a. E-Commerce Platforms:
- Scenario: An e-commerce company operates multiple data centers across different regions.
- Solution: P2P replication ensures that product, inventory, and order data are consistent across all centers. If one center goes down, others can continue operations without data loss.
b. Financial Institutions:
- Scenario: A bank has branches in various countries, each requiring real-time access to customer account information.
- Solution: P2P replication synchronizes data across all branches, allowing any branch to process transactions independently.
c. Distributed Reporting Systems:
- Scenario: A multinational corporation needs to generate reports from a centralized database.
- Solution: P2P replication distributes the reporting load across multiple nodes, improving performance and availability.
d. Real-Time Gaming Applications:
- Scenario: An online gaming company needs to maintain player profiles and game statistics across multiple regions.
- Solution: P2P replication ensures that player data is consistent and accessible from any region, providing a seamless gaming experience.
Source: MadeSimpleMSSQL
6. Best Practices for Peer-to-Peer Replication
- Limit the Number of Nodes: To avoid performance degradation, limit the number of nodes to a manageable level.
- Monitor Replication Agents: Regularly monitor the Log Reader and Distribution Agents to ensure they are functioning correctly.
- Implement Conflict Detection: Enable conflict detection to identify and resolve data conflicts promptly.
- Regular Backups: Perform regular backups of the distribution databases to prevent data loss.
- Schema Changes: Plan schema changes carefully, as they require reinitialization of the replication topology.
Source: SQLServerCentral
7. Limitations of Peer-to-Peer Replication
- Enterprise Edition Only: P2P replication is available only in the Enterprise edition of SQL Server.
- No Filtering: Row and column filtering are not supported.
- Complex Conflict Handling: Manual intervention is required to resolve data conflicts.
- Performance Overhead: As the number of nodes increases, replication performance may degrade.
Source: SQLShack
8. Troubleshooting Peer-to-Peer Replication
- Replication Agent Failures: Check the SQL Server error logs and replication monitor for error messages.
- Data Conflicts: Investigate conflict tables to identify and resolve conflicting data.
- Performance Issues: Monitor system resources and replication latency to identify bottlenecks.
Source: SQLServerCentral
Peer-to-Peer Replication in SQL Server provides a robust solution for high availability, load balancing, and fault